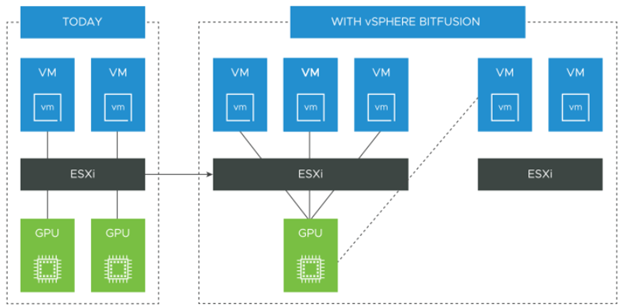
GPUs (Graphical Processing Unit) were created in the 70s to speed up the creation and manipulation of images. They were quickly adopted by game console manufacturers to improve the fluidity of graphics. It was in the 2000s that the use of GPUs for computing outside of graphics began. Today the popular use of GPUs concerns the AI (artificial intelligence) and ML (Machine Learning). More history on the Wikipedia site: Graphics processing unit – Wikipedia. This is why these GPUs are found in datacenter servers because IA and ML type applications require many calculations that are executed in parallel, which a conventional processor (CPU) would have difficulty doing this function. Indeed a CPU is the central element of a server which is there to execute lots of small sequential tasks, very fast and at low latency, for that it can count on about sixty cores per CPU (at the date of writing this article). A GPU on the other hand, is made to perform thousands of tasks in parallel thanks to its thousands of cores which compose it. The downside to a GPU is its cost, it can run into tens of thousands of dollars, so you have to make sure it is being used properly all the time. The ideal is to be able to share it so that it can be used simultaneously by several applications in order to be close to consuming all the resources. This is the credo of Bitfusion solution acquired by VMware in 2019 and which is now available as an add-on to vSphere. The GPUs are installed on the hypervisors and form a pool of GPUs which will be accessible by the applications directly hosted on these hypervisors or via the IP network if the applications are hosted on other hypervisors, the applications can even be hosted on physical servers or be based on Kubernetes container. The use is reserved for Artificial Intelligence or Machine Learning type applications using CUDA routines. CUDA was developed by NVDIA to allow direct access to GPUs for non-graphics applications. Thank to Bitfusion, Applications can consume a GPU, several GPUs or just a portion of a GPU (in reality it is the memory of the GPU that is shared). Once consumption is complete, the applications release the allocated GPU resources which then return to the pool for future requests.
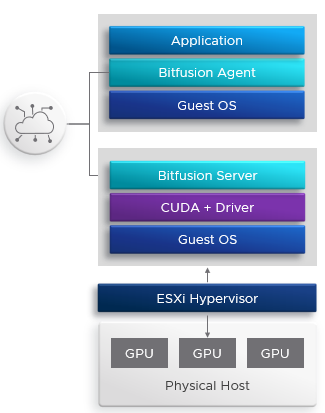
From a technical point of view, Bitfusion requires the installation of components on both sides. On the hypervisors side that have GPUs, a virtual appliance must be deployed on each one that can be downloaded from the VMware site. For clients (VM, Bare Metal or Kubernetes containers / PODs) who will consume GPUs resources, a Bitfusion client must be installed, which will allow the interception of CUDA calls made by the application to transfer them to the Bitfusion appliances via the IP network. It is transparent to the application.
Since the exchanges between clients and Bitfusion appliances go through the IP network, it is preferable to have at least a 10 Gb/s network, you generally need 1 10 Gb/s network for 4 GPUs.
Leave a Reply