Les GPUs (Graphical Processing Unit) ont été créés dans les années 70s pour accélérer la création et la manipulation des images. Elles ont vite été adoptées par les constructeurs de console de jeux pour améliorer la fluidité des graphismes. C’est dans les années 2000 qu’a commencé l’utilisation des GPU pour faire des calculs en dehors du domaine du graphisme. Aujourd’hui l’utilisation en vogue des GPUs concernent les domaines d’IA (intelligence artificielle) et de ML (Machine Learning). Plus d’historique sur le site de Wikipédia : : Graphics processing unit – Wikipedia.
C’est pour cela que dans les serveurs des datacenters on retrouve ces GPUs car les applications de type IA et ML nécessitent de nombreux calculs qui s’exécutent en parallèle, ce qu’un processeur classique (CPU) aurait du mal à faire de par sa fonction. En effet une CPU est l’élément central d’un serveur qui est là pour exécuter plein de petites taches séquentielles, très rapide et à faible latence, pour cela il peut compter sur une soixantaine de cœurs par CPU (à date de la rédaction de l’article). Une GPU quant à elle, est faite pour exécuter des milliers de taches en parallèle grâce à ses milliers de cœurs qui la compose.
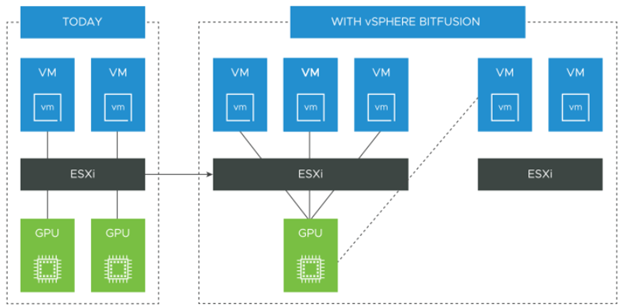
L’inconvénient d’une GPU c’est son coût, cela peut atteindre des dizaines de milliers d’euro, il faut donc s’assurer qu’elle soit bien utilisée tout le temps. L’idéal est de pouvoir la partager pour qu’elle soit utilisable simultanément par plusieurs applications afin d’être proche de consommer l’ensemble des ressources.
C’est le crédo de Bitfusion solution rachetée par VMware en 2019 et qui maintenant fait partie d’un add-on à vSphere. Les GPUs sont installées sur les hyperviseurs et forment un pool de GPUs qui seront accessibles par les applications directement hébergées sur ces hyperviseurs ou via le réseau IP si les applications sont hébergées sur d’autres hyperviseurs, les applications peuvent même être hébergées sur des serveurs physiques ou être à base de container Kubernetes. L’usage est réservé aux applications types Intelligence Artificielle ou Machine Learning utilisant les routines CUDA. CUDA a été développé par NVDIA pour permettre l’accès directe à des GPUs pour des applications non graphiques.
Les applications peuvent consommer une GPU, plusieurs GPUs ou simplement un portion de GPU (en réalité c’est la mémoire de la GPU qui est partagée). Une fois la consommation terminée, les applications libèrent les ressources GPUs octroyées qui retournent ensuite dans le pool à la disposition de futures demandes.
D’un point de vue technique, Bitfusion nécessite l’installation de composants de part et d’autre. Coté hyperviseurs qui possèdent les GPUs, il faut déployer sur chacun une appliance virtuelle téléchargeable à partir du site VMware. Pour les clients (VM, Bare Metal ou containers/PODs Kubernetes) qui vont consommer les ressources GPUs, il faut installer un client Bitfusion, ce dernier permettra d’intercepter les appels CUDA fait par l’application pour les transférer à l’appliances Bitfusion via le réseau IP. C’est transparent pour l’application.
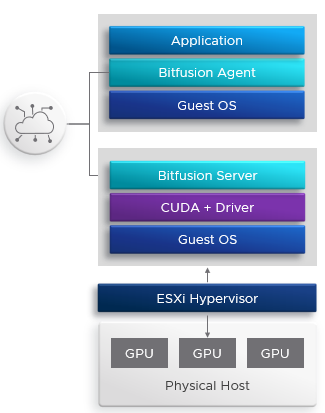
Du fait que les échanges entre les clients et les appliances Bitfusion passent par le réseau IP, il est préférable d’avoir au minimum un réseau 10 Gb/s, il faut compter en général 1 réseau 10 Gb/s pour 4 GPUs.
2 commentaires